
Auf einen Blick
Sind KI-Bilder illegal?
1| Größte Verletzung von Urheberrechten
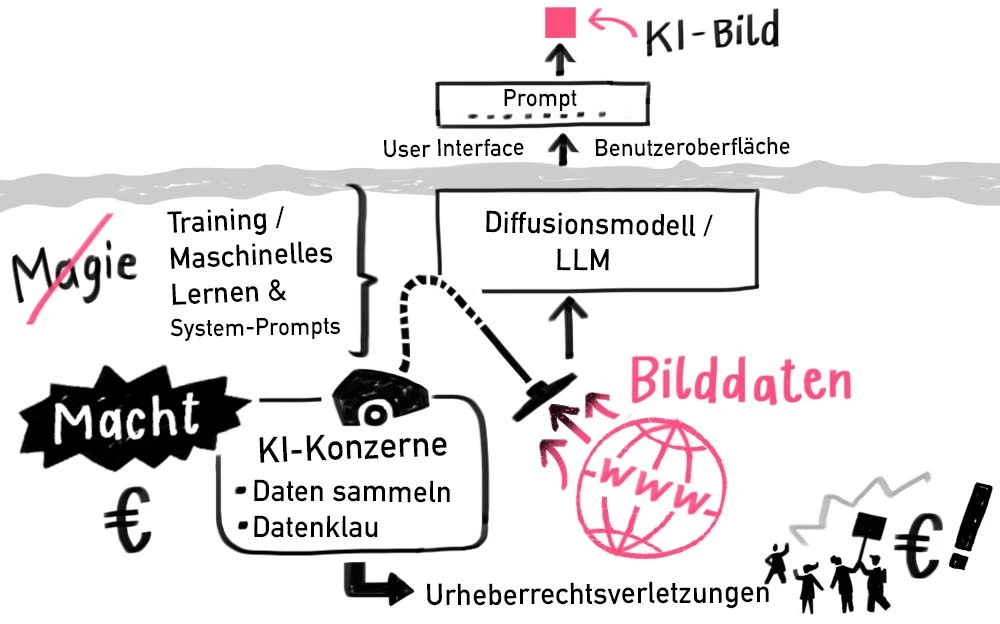
Wenn über generative KI geschrieben wird, werden oft Teile humanoider Roboter oder leuchtende Gehirne, halb Mensch- halb Netzwerk, gezeigt. Diese Bildsprache vermittelt den Eindruck, dass KI-Modelle eigenständig funktionieren und aus dem Nichts bunte Bilder generieren. So ist es nicht!
Bildgeneratoren werden mit Millionen von vorhandenen Bildern und Illustrationen aus dem Internet trainiert. Das Absaugen dieser Werke erfolgt ohne die Zustimmung der Urheberinnen und Urheber. Die Daten werden geklaut! Die Urheberrechte werden verletzt. Das Ausmaß des Ziehens von Werken für Trainingsdaten ist die größte Urheberrechtsverletzung, die es je gegeben hat.
KI-Modelle benötigen diese Daten, um durch maschinelles Lernen Bilder auf Basis einer Texteingabe (Prompt) neu zusammenzusetzen. Dafür sind sehr viele Daten erforderlich, denn für das Training ist eine unvorstellbar große Anzahl notwendig, um zu Ergebnissen zu gelangen.
»Das Internet ist kein Selbstbedienungsladen!«
Prof. Dr. Alke Martens, Universität Rostock, Zitat aus einem Kurzvideo/LinkeIn
2| Verdrängung von Bildschaffenden
Das Trainieren der KI-Modelle erfolgt nicht nur ohne Zustimmung der Kreativen, sondern auch ohne Entlohnung. Illustratorinnen und Illustratoren, sowie andere Berufszweige aus dem Bildbereich kucken in die Röhre. Die Wirtschaftlichkeit der Selbstständigen in diesen Bereichen leidet stark.
Wenn Kreative durch den Einsatz von generativer KI ihre Arbeit verlieren, ist es an der Zeit, ein Grundeinkommen für kreative Berufe zu verwirklichen!
Im Bildbereich beginnen Verlage zunehmend Urheberrechtsklagen gegen Anbieter von KI-software bei Gerichten einzureichen.
»Wir begrüßen eine Klage gegen eines der KI-Big-Tech-Unternehmen aus dem Buchbereich ausdrücklich, und freuen uns sehr, dass die Klage sowohl Text als auch Illustration umfasst.«
Katharina Uppenbrink, Geschäftsführerin der Initiative Urheberrecht
Zitat aus: Der Kampf um den Drachen Kokosnuss. Verlagsgruppe Penguin Random House klagt gegen OpenAI, 31.03.2026
Warum haben KI-Bildgeneratoren Vorurteile (Bias)?
KI-Bilder sind neutral oder objektiv. Nein!
Bias stammt aus dem Englischen und bedeutet Voreingenommenheit und Vorurteil. KI-Bias entsteht durch die Unausgewogenheit (Einseitigkeit) der Trainingsdaten. Das heißt, die Trainingsdaten, mit denen die Modelle lernen, enthalten bereits gesellschaftliche Vorurteile. KI-Systeme übernehmen diese und verstärken sie. Bei der Bildgenerierung werden bestehende Stereotype wiederholt und vervielfältigt.
So wird eine visuelle Norm vermittelt, die nicht der Realität entspricht. Ein Beispiel: Wenn Frauen historisch weniger sichtbar waren, sind sie auch in KI-Bildern weniger sichtbar. Wenn bestimmte Rollen klischeehaft verteilt sind, reproduziert KI genau diese Muster. Das erfolgt unterschwellig, nicht gleich erkennbar. Das Problem der fehlenden Diversität in generierten Bildern habe ich in einem früheren Beitrag schon erwähnt.
Es gibt verschiedene Bias-Arten:
- Geschlechterbias (Gender Bias)
Männer sind als Führungskräfte und Erfolgreiche überrepräsentiert, während Frauen in Pflege-, Service- oder ähnlichen Berufen dargestellt werden.
- Rassistischer Bias
Personen mit hellen Hautmerkmalen sowie die westliche Kultur sind überrepräsentiert und werden in positiveren Kontexten gezeigt. Personen of Color und ethnische Minderheiten werden exotisierend und marginalisiert dargestellt. - Schönheits-Bias
Die Algorithmen enthalten Vorurteile darüber, was als schön bzw. normal gilt. zum Beispiel jung, schlank, symmetrische Gesichter, helle Haut, große Augen, schmale Nase.
Frauen werden meist in schönheitsbezogenen Kontexten (Kosmetik, Diäten) und/oder sexualisiert dargestellt. Abweichende Körperformen oder sichtbare Behinderungen sind nicht repräsentiert.
- Klassen-Bias
KI-Bilder zeigen westlich geprägte Lebensstile. Zu sehen sind wohlhabende Personen mit hohem Lebensstandard, Sauberkeit und Ordnung. Armut und zum Beispiel beengte Wohnungen werden nicht oder nur klischeehaft dargestellt.
Biases können gewollt sein. Es kommt darauf an, welches Unternehmen hinter einem KI-System steht, wer die System-Prompts setzt, wer die eigene Meinung vermehren will – und wer die Macht hat.
Warum schaffen Bildgeneratoren ökologische Probleme?
Bild-KI ist eine immaterielle Technologie. Nein!
Für den Nutzen und den Bau von KI-Systemen werden enorme Rechenkapazitäten benötigt. Das sind einerseits Rechenleistungen für jede einzelne Bildgenerierung und andererseits für die Datenspeicherung und das Training.
All das hat einen enormen Stromverbrauch zur Folge. Wenn der Strom nicht aus erneuerbaren Energien stammt, entstehen direkt CO₂-Emissionen, die zum Klimawandel beitragen. Zusätzlich entsteht ein sehr hoher Wasserverbrauch, unter anderem für die Kühlung der Rechenzentren.
Bilder und KI-Slop »aus Spaß« zu erstellen ist eine völlig unnötige Verschwendung von Ressourcen!
Auch die in den Systemen verbauten Chips (Haupthersteller: Nvidia) belasten die Umwelt. Sie werden unter Einsatz seltener Erden produziert und transportiert. Zudem veralten sie schnell, wodurch Elektroschrott entsteht.
Alles in allem steckt hinter KI-Bildgeneratoren und jedem generierten Bild eine ressourcen- und kostenintensive Infrastruktur! Diese können sich nur die weltweit größten Tech-Konzerne leisten.
Wer trainiert KI-Bildgeneratoren?
Bild-KI ist selbstlernend. Alles automatisiert. Nein!
Die Unmengen an Bilddaten, die rechtswidrig gezogen werden, werden gesammelt, gelabelt und verschlagwortet. Diese Arbeit wird nicht von KI, sondern von Menschen, genauer gesagt von Datenannotatoren und Content-Moderatoren, erledigt.
Hinter der Magie steckt also menschliche Arbeit, die zudem sehr schlecht bezahlt wird, nämlich pro Aufgabe. Eine solche Aufgabe im Bildbereich kann beispielsweise lauten: »Ist auf diesem Bild eine schlange? Ja/Nein«. Ohne diese Beschriftungen könnten KI-Systeme nicht lernen, was sie sollen. Auch nachdem KI-Modelle trainiert sind, geht die Arbeit weiter. Dann geht es beispielsweise um das Korrigieren von Fehlern.
In der gesamten Datenarbeit sind hochqualifizierte Menschen im globalen Süden sowie in Europa beschäftigt.
»Eine Studie aus dem Jahr 2019 zeigt, dass Datenarbeit rund 80 % der Arbeitsstunden in der Entwicklung von KI-Technologien ausmacht. Das heißt, ohne Datenarbeiter und Datenarbeiterinnen gibt es keine KI. Die Weltbank schätzt, dass weltweit zwischen 150 und 430 Millionen Menschen in der Datenarbeit tätig sind.«
Dr. Milagros Miceli, Weizenbaum Institut
Zitat aus: Fachgespräch zu Arbeitsbedingungen von Data Labelern,15.04.2026, Bundestag
Als Illustratorin nutze ich keine KI-Bilder
Aus den genannten ethischen und auch aus kollegialen Gründen verzichte ich in meiner Arbeit auf den Einsatz generativer KI-Bilder.
Hier teile ich mein Input, welches für die Vorbereitung dieses Beitrags sehr hilfreich war:
- Publikation Weizenbaum Institut
- aktuelle Veranstaltungen der gemeinnützigen Organisation SUPERRR Lab
- aktuelle LinkedIn Beiträge von Informatik Professorin Dr. Alke Martens
- »Was Lehrende über KI wissen sollten«, Volkshochschule Berlin



